OO第三单元总结-社交网络
题目回顾:
本单元的题目较为特殊,有着较少的题目描述,主要题目靠 JML 间接提供。我会将题目和官方包放在 [github 仓库](s7777777h/BUAA-OO: buaa oo 个人代码 (github.com))中,这里不过多赘述。
第一次作业:
建立一个较为朴素的社交网络,维护人际关系的整个图。
第二次作业:
在网络中引入公众号和文章的概念,每个人可以加入公众号贡献文章,也可以接收文章。
第三次作业:
引入消息和emoji的概念,每个人可以发送不同类型的消息,同时emoji消息会给emoji增加热度,需要进行发送Message操作和维护emoji操作。
架构设计
存储方式
本次作业中选取恰当的容器较为重要。对于 Unit3 而言含 id 对象使用 HashMap<Integer, Object> 较为合适,对于可重复的对象使用 HashMap<Integer, ArrayList<Object>> 较优。
对于 receivedArticle 成员,有从头部插入,删除特定成员,询问前五个内容等操作,由于需要高效函数和维护其内部顺序,理论上使用 LinkedList 较为合适。
实际上,由于 LinkedList 的内存空间分布并不连续,CPU 访存时 cache 缺失率较高,实际的效率会严重退化。一个比较好的实现方式是自己写一个 ListItem ,然后使用 HashMap<Integer, ArrayList<ListItem>> 维护。同时要维护链表头。.
图的存储和维护
本单元的社交网络本质上是一个图,在我的架构设计下,每个 Person即是一个点,而边的关系依赖 HashMap <Integer, PersonInterface> acquaintance 来存储。在 addRelation 和 modifyRelation 时直接朴素维护。
方法高效实现
许多方法十分简单,没有讨论价值。但是有很多方法如果不进行优化会导致时间复杂度过高导致 CTLE ,这里分享一下一些需要优化的方法
queryTagValueSum
通过在 Tag 中动态维护 valueSum 成员实现动态维护。
具体讲,在 Tag 中的 delPerson 和 addPerson 中,要扫一遍 Tag 中的其他成员,如果和操作的 person 有连接,就加 / 减二倍的 value 。
同时,在 Network 调用 modifyRelation 和 addRelation 时,要在 Tag 中写相应的 modifyRelation 方法来维护。
queryCoupleSum && queryBestAcquaintace
对于每个人,维护一个 bestAcId 和 bestAcValue,在增加 bestAcId 的value 和增加新人时用 $O(1)$ 维护,在 delPerson(bestAcId) 或使用负数 modify 其 value 时使用 $O(n)$ 维护。
qcs 使用优化后的 qba $O(n)$ 扫一遍就行。
注:最差情况下,由于 qba 的单次维护需要 O(n),而没有优化的 qba 的查询也是 O(n),所以看似 qba 的维护实际退化了
但是实际上,由于 qba 指令会在 qcs 中循环使用,此时会把 qcs 的时间复杂度变为 O(qba) * n ,而单个指令时间复杂度 O(n) 是可接受的,O(n^2) 是不可接受的,故牺牲维护的性能,以大幅提高 qcs 的效率
queryShortestPath
使用朴素 bfs ,时间复杂度为 $O(n +m )$
deleteArticle && queryReceivedArticle
使用链表 HashMap<Integer, ArrayList<ListItem>> 维护,可见前文。
类图
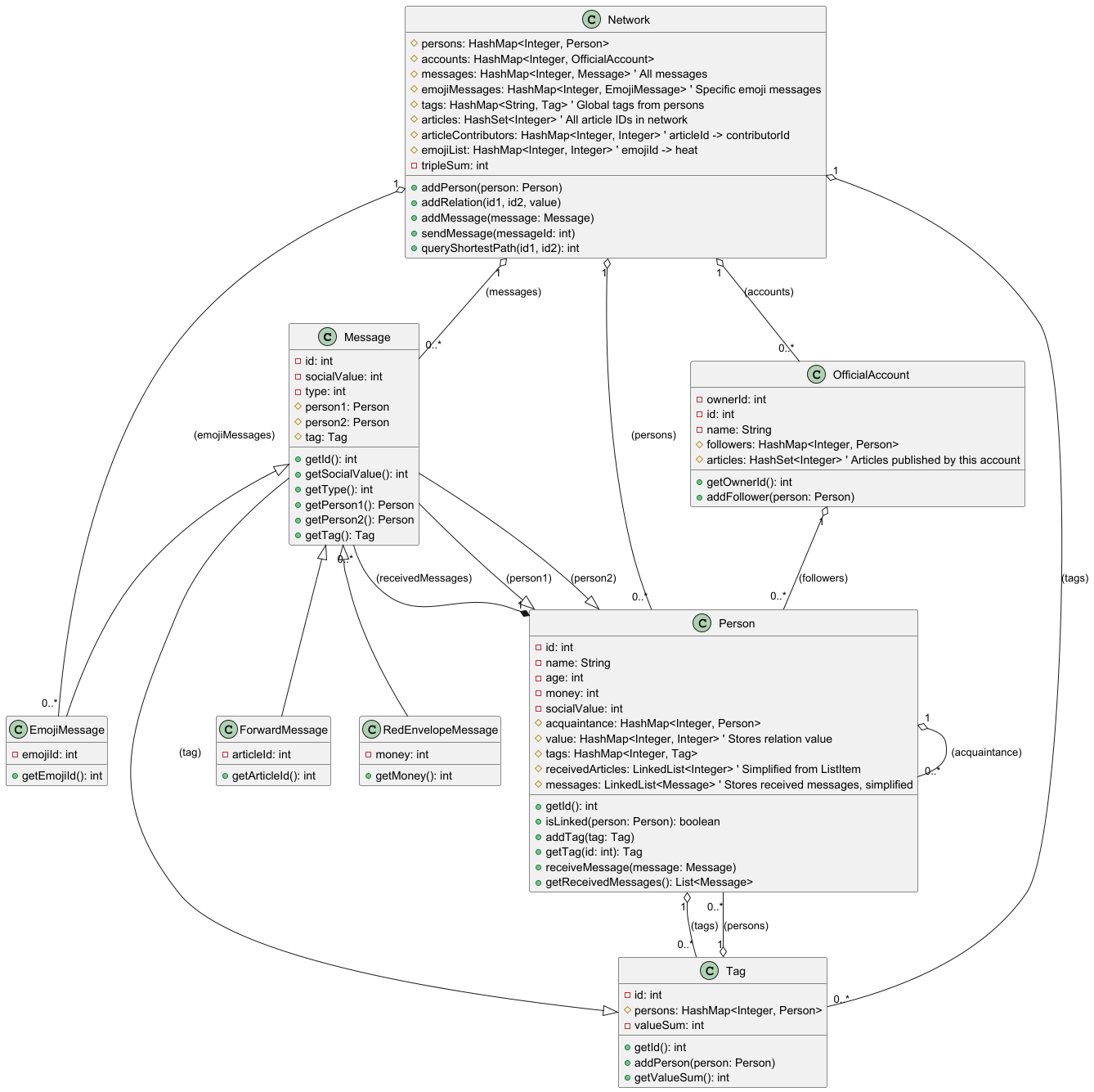
测试过程分析
对单元测试、功能测试、集成测试、压力测试、回归测试的理解
这部分是博客作业要写的www
单元测试
单元测试,从定义来看是对功能的最小单元:函数进行测试。单元测试在与 JML 配合后,能起到非常好的效果。对整个系统直接进行测试,往往会忽视掉很多边界条件和分支条件,而单元测试可以更细致的覆盖每个分支。
当然,单元测试也有缺点,单元测试往往不能反映各个功能组合起来的性能问题 ,且不好测试各个类之间协同的关系。
功能测试
从用户角度直接测试功能。主流评测机一般都是这个模式。
相比其他测试更加容易进行,但是对于一些隐藏的bug很难测出。
集成测试
对于类和方法之间的协同关系进行测试。
压力测试
构造极端数据测试性能,查找性能瓶颈,一般在正确性测试结束后进行。
往往仅需要进行几组特定设计的数据即可进行。
回归测试
迭代后测试代码是否破坏原有功能。
需要做到高度自动化,在长期迭代的项目中回归测试极为重要。都去给我写评测机。
数据构造策略
基于大模型的数据构造策略
让大模型思考构造策略,生成多样的强力数据(你就说好不好用吧)
以下是 Gemini 2.5 Pro 编写的数据生成器中采取的不同数据构造策略。
1 | strategies_to_use = [ |
构造压力测试数据
图上的压力测试主要要考察完全图,首先通过 ln 设计一个稠密的图。
在设计数据时,应当对相对复杂,时间复杂度可能较高的指令进行测试(如 qtvs ),每组数据专精于一种指令的询问,以测试每一种指令的性能。
创造异常/避免异常
在构造数据时,测试代码的异常处理同样较为关键,需要有一定比例的数据含有异常,一定比例的数据没有异常。
异常大多数来自 id 冲突和 id 未找到,在设计数据生成器时,新的 id 生成不能完全采取随机策略,在一些测试异常用的数据中应当有选择性地使用之前使用过的 id ,来测试异常处理能力。
使用评测机进行高效的测试
本单元评测机的核心是数据生成器,checker 的核心逻辑较为简单,就是一个纯的对拍。
本单元的评测机我已同步到 [github 仓库](s7777777h/BUAA-OO: buaa oo 个人代码 (github.com)), 其中 hw11 的评测机我会在互测结束后延迟发布。
编写可以定位错误的评测机
评测机的数据往往很大,一般 10000 条左右,简单的 WA 结果是很难让我们定位错误原因的。
在评测机打印出的日志中添加一些错误分析信息能够很好的帮助解决这个问题。具体来讲,评测机应当能够输出:
- 发生 RE 时的 stderr
- 错误发生的行数,在这一行,输入数据是什么,正确输出是什么,错误输出了什么
这里举个我的评测机的例子:
1 | --- Detailed Differences (First 10 Mismatches) --- |
通过这样的评测机日志就可以定位到 qtvs 错误,进而寻找相应的代码。
通过二分在茫茫数据中找到原因
定位到行数有时还无法帮我们找到bug,此时只能尝试化简数据,尽量找到怎么出错的。
化简数据的流程大概是:
删除错误行后面的所有数据
删除错误行前面的一部分数据,运行评测机
如果评测机仍然报错,继续删除
如果评测机没有报错,撤回,缩小删除规模
这需要你的评测机具有选择使用本地测试数据的功能,这是很关键的。
大模型使用心得
大模型使用最重要的是选取高效的模型,一个好的高效的模型会使你事半功倍。强烈推荐使用谷歌的 Gemini 2.5 Pro ,功能十分强大。
使用大模型,第二重要的是提供一个高效的 Prompt。
一个 Prompt 是否高效,关键在于能否清晰表达需求。在 Prompt 中不要添加需求以外的东西,反面教材: “你是一个 xxx 专家”。
一些比较好的示例:
1 | 帮我写一个python小工具,读取src文件夹里所有Java文件,将其内容合并到out.md里面,不同文件代码放到不同的代码块里 |
(↑写这个是因为 Gemini 不支持直接的 Java 文件,也不支持同时输入太多文件,写一个这样的工具来合并代码方便丢给 AI)
1 | 在我的面向对象课程中,我们有多次的增量Java项目开发,为了方便批量测试,我需要一个自动生成数据的输入数据生成器(不需要输出数据)。我会把题目描述发给你。你的数据生成器应当满足以下要求: |
1 | 再写一个对拍器,读取std文件夹里的jar文件(保证只有一个),对testjar文件夹下所有jar依次使用data文件夹下的数据进行对拍测试,要求: |
当然,对于一些复杂的问题, AI 往往不能一下就给出令人满意的结果,这时最重要的就是要有耐心,一次不行问十次。
据不完全统计 s7h 写一个评测机平均使用 25w token
再其次,就是提供充分的资料和信息。提供信息一定要把整个指导书和代码全部给AI,让他有一个更充分的了解。
同时,给的信息要尽量细致,来引导 AI 的思考方向。
例如,以下第一个看起来很不错,但是实际效果会比第二种差点意思:
1 | 帮我检查我的 qtvs 为什么不对 |
1 | 我的 qtvs 的实际值总比正确值偏小,帮我检查一下。 |
性能问题和修复情况
第二次作业强测挂了个点(CTLE),使用 Intelij Profiler 分析后发现是 qtvs 的性能问题;
**修复:**在 Tag 中动态维护 valueSum 成员实现动态维护。
具体讲,在 Tag 中的 delPerson 和 addPerson 中,要扫一遍 Tag 中的其他成员,如果和操作的 person 有连接,就加 / 减二倍的 value 。
同时,在 Network 调用 modifyRelation 和 addRelation 时,要在 Tag 中写相应的 modifyRelation 方法来维护。
对于规格和实现分离的理解
规格实际上是个题面,而实现是解题的过程。
规格的作用在于
- 更加清晰的表述需求
- 更加方便的进行单元测试
规格只需要让人清晰的了解要做什么就好,而不需要在意效率。
而实现者应当在实现规格正确性的同时,兼顾效率。例如以下规格:
1 | /* @normal_behavior |
其JML规格关注的是其目标,而实现则需要用快速幂等算法实现。
JUnit 单元测试
使用 JUnit 对规格进行单元测试,主要有以下这几点:
对于正确性的检测
JUnit 单元测试应当尽量的 JML 中提供的 ensures 原文算法(如果有给出)。如果没有给出算法,可以牺牲性能,不做额外的优化,以保证单元测试的绝对正确。
对于不变式的检测
在 JUnit 中构造 repOk 方法,以检测对象不变式的正确性。
由于课程组禁用了 reflection 特性,作业中实际上无法使用。
但是实际工程开发是可行的。
对于纯洁性的检测
应当通过给方法调用前的容器创立深拷贝,方法调用后使用 strictEquals 方法来比较纯洁性。
本单元的测试中,由于课程组给的 getPersons 是浅拷贝,且 PersonInterface 的 getter 数量不足,实际上无法进行狭义的深拷贝。但是可以通过在生成数据式生成两份一模一样的数据来模拟深拷贝。
本单元学习体会
JML 规格作为严谨的,非自然语言的规格表述,可以作为很好用的工具来进行甲方和乙方之间的沟通交流和需求表述,并且方便自动化测试的进行,同时也能让代码的编写者的思维脉络更加清晰。
现在,随着大模型的兴起, JML 也可以作为高效的人与机器交流的语言,让大模型帮我们编写代码和 Debug 。
在 JML 以外,要拥抱大模型,拥抱最先进的生产技术,学会更加明智地使用。